1. 서론
해양에서 용존산소(Dissolved Oxygen; DO)는 일차생산자의 광합성과 유기 생명체의 호흡, 질산화와 탄소순환 등 해양의 생지화학적 과정들과 밀접한 관계가 있다. 또한, DO 농도는 COD(Chemical Oxygen Demand), WQI(Water Quality Index)와 같은 수질 지표의 결정 인자 중 하나이기도 하다. 한편, 빈산소수괴(DO 농도 < 2 mg L-1)는 해양 유기체의 폐사, 번식 감소 및 서식지의 변화를 발생시켜 해양생물자원의 감소를 유발한다(Baden et al., 1990; Diaz and Solow, 1999; Paerl et al., 1998; Yin et al., 2004). 따라서 DO 농도의 예측·예보는 해양생태계의 관리와 지속 가능한 수산어업을 위한 필수과제이다.
DO 농도의 예측·예보 모형에는 QUAL2E, WASP와 같은 확정론적 모형과 시계열분석과 같은 통계학적 모형이 이용되어 왔다(K-water, 1996; Huck and Farquhar, 1974; Ahn et al., 2001). 최근에는 데이터를 기반으로 하는 기계학습 기법인 인공신경망 모형을 이용한 DO 농도 예측 연구가 활발히 진행되고 있다. 그 중에서도 Recurrent Neural Network(RNN) 계열의 Long Short-Term Memory(LSTM) 모델이 우수한 예측성능을 보이고 있다(Eze and Ajmal, 2020; Li et al., 2021; Lim et al., 2020). 하지만 대부분의 연구가 연못과 같은 정적인 수괴나 하천을 대상으로 하고 있으며, 연안 하구역을 대상으로 한 DO 예측 연구는 미흡한 실정이다. 또한, 대부분의 예측이 수 시간 또는 1일 예측으로 장기예측에 대한 고찰이 미비하다.
하구의 DO는 수질을 결정하고 생태계와 밀접한 관계를 갖는 중요 환경인자이다(Breitburg et al., 1994). 그러나 하구는 담수 유입의 영향으로 밀도와 성층이 시시각각 변화하는 해역으로 DO 농도의 표·저층 불균형이 존재한다. 또한, 육지로부터 유입된 다량의 영양염 및 유기물에 의한 산소 소모 증가로 빈산소수괴가 빈번히 발생하는 해역이다(Rosenberg et al., 1990). 이처럼 DO는 하구의 중요 환경인자이나 지역적 특성으로 인해 DO 농도에 대한 불확실성을 내포하고 있다.
낙동강 하구는 1987년에 준공된 하구둑의 건설로 조류가 지배하던 혼합 기작이 담수가 지배하는 형태로 바뀌었다. 그결과 낙동강 하구의 혼합 특성과 해수 순환의 변화를 야기했다(Jang and Kim, 2006). 또한, 낙동강 상류의 과도한 영양염 부하로 강우시 하구역의 부영양화가 심각한 실정이다(Song et al., 1993). 낙동강 하구의 수질 지표 WQI는 최근 5년 동안 3~5등급으로 주변 해역보다 오염된 것은 물론 특별관리 해역인 마산만의 오염 정도와 유사하다(MEIS, 2020).
본 연구에서는 LSTM 모델을 사용하여 낙동강 하구역의 DO 농도를 예측하였다. 연구는 case study로 진행하였으며 case는 모델 매개변수(parameter)와 예측변수(predictor)로 구성하였다. 모델 매개변수 case study를 통해 DO 농도 예측의 최적 모델 조건을 찾고자 하였다. 예측변수 case study를통해 DO 농도 예측에 적합한 환경인자를 조사하였다.
2. 재료 및 방법
2.1 Study Area and Analysis of Data
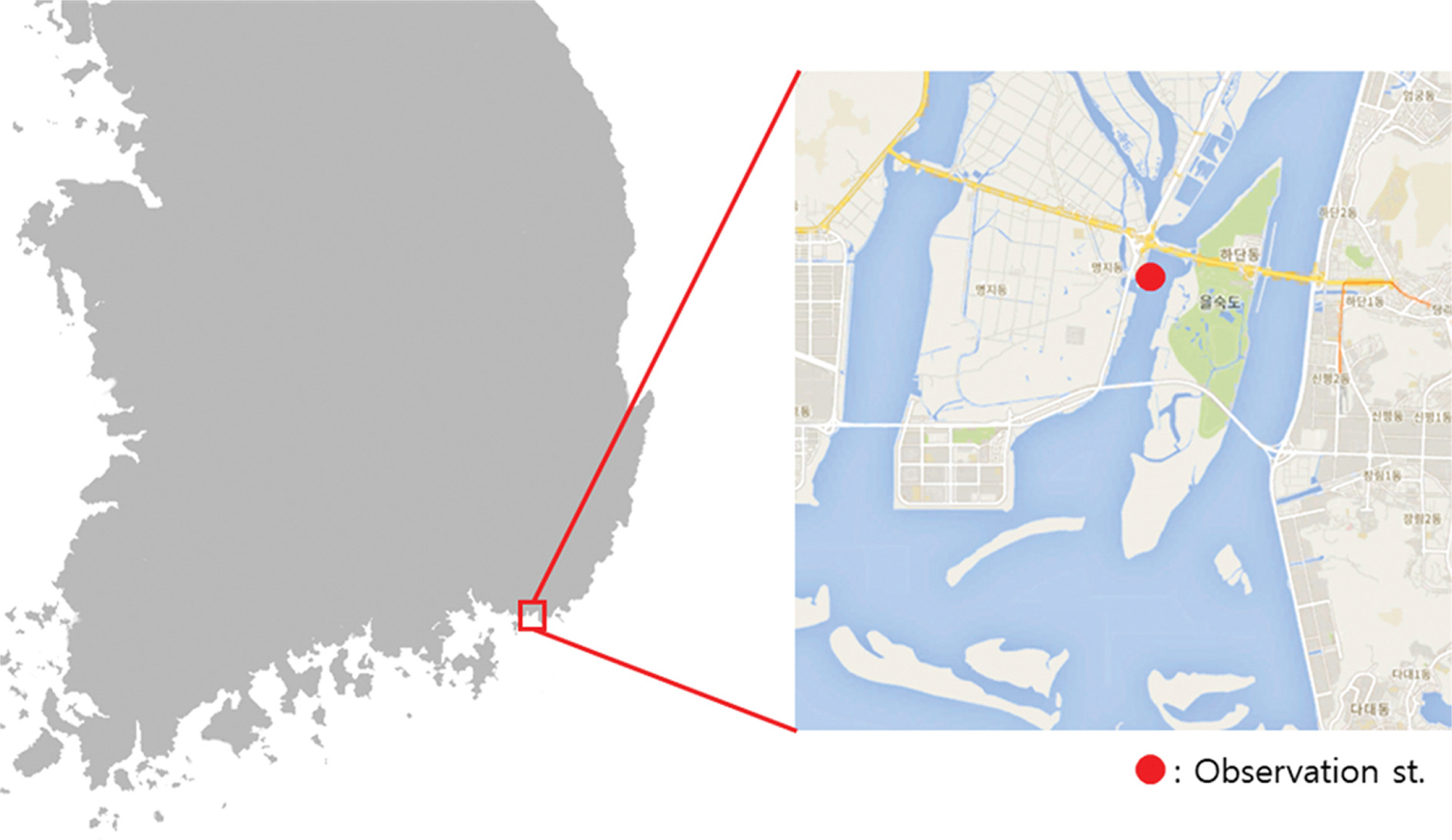
본 연구에서는 해양환경공단의 해양수질자동측정망 ‘낙동 명지’정점의 자료를 사용하였다(Fig. 1; KOEM, 2020). 자료는 약 5년간(2015.01.01.~2019.11.30.)의 5분 간격 시계열 자료로 구성되어 있다. 자료의 항목별 평균, 표준편차, 결측 비율은 Table 1에 나타내었다. 해당 자료를 1시간, 1일 평균하여 각각 시간 예측, 일 예측에 사용하였으며, 결측치는 선형 보간하였다. data point의 수는 시간 자료, 일 자료 각각 43,078개, 1,793개이다. 자료의 70%는 기계학습에 사용하였으며 나머지 30%를 모델 검증에 사용하였다. 예측변수는 수온, 염분, pH, COD, NH3, NO3, TN, PO4, TP, Chl.a, DO 11가지이며, 반응변수는 DO이다. 즉, 과거 예측변수 자료를 입력자료로 하여 미래의 DO 농도를 예측하는 것을 목표로 한다. 예측변수와 반응변수 모두 다음 식을 사용하여 평균 = 0, 표준편차 = 1로 표준화(Standardization)하여 기계학습에 사용하였다.
여기서 X는 변수, μ는 평균, σ는 표준편차이다.
2.2 LSTM Structure
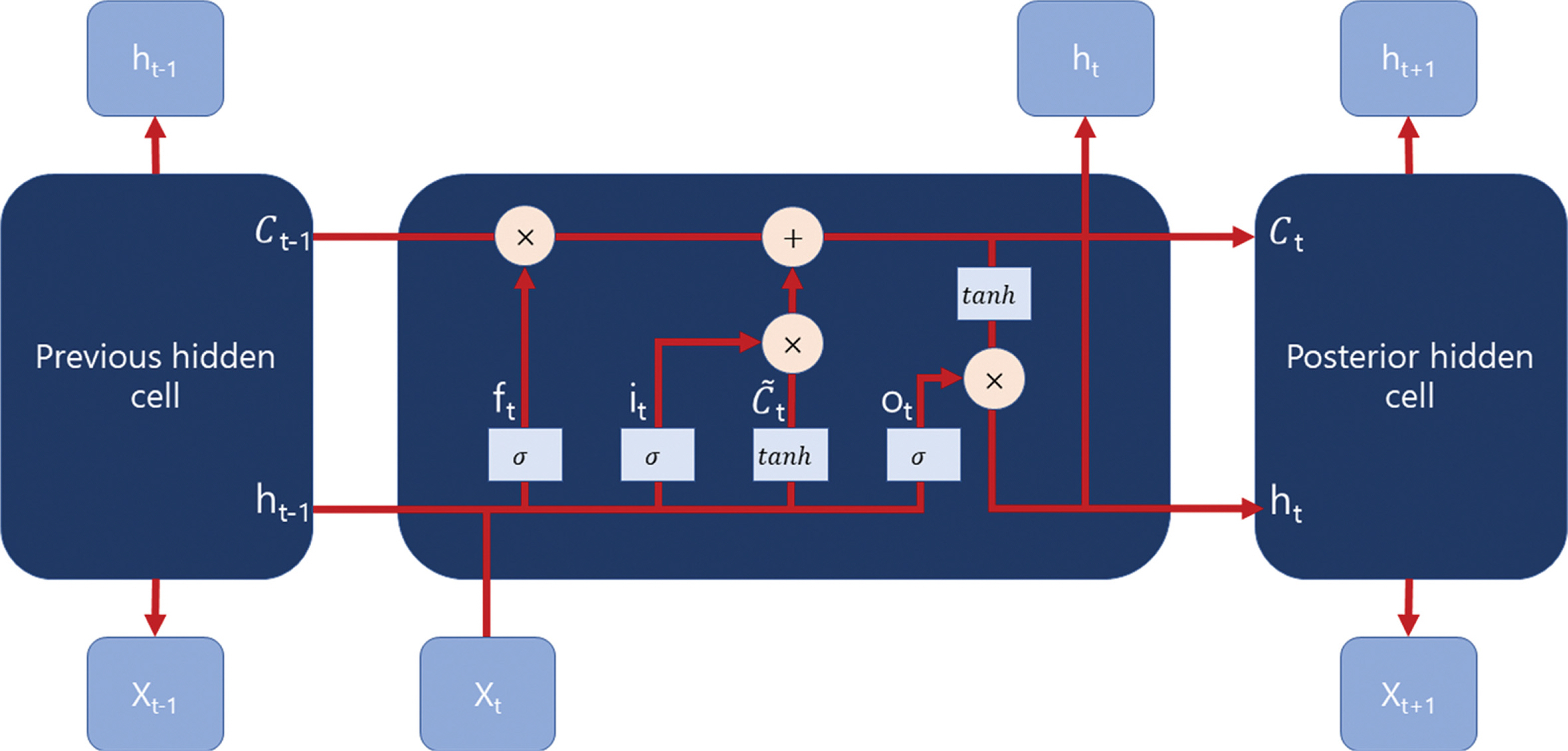
LSTM은 RNN 계열의 모델이다. RNN은 Rumelhart et al.(1986)의 연구에 기반하여 개발되었다. RNN 모델은 hidden cell간의 순환구조를 이루고 있는 것이 특징이다. 이러한 구조는 신경망 내부에 이전의 state 정보를 저장할 수 있게 해주므로 sequence data를 입력자료로 한다(Dupond, 2019; Tealab, 2018). 따라서 RNN은 문자열, 음성 인식 그리고 시계열 자료와 같이 시변적 특징을 지니는 자료 처리에 적합하다. RNN은 간단하면서 강력한 성능을 보이나 실제로는 입력자료인 sequence data의 길이가 길어질수록 학습 정도가 떨어지는 문제점이 있다. 이러한 문제를 기울기 소실(vanishing gradient)이라 하며 Bengio et al.(1994)이 제시하였다. RNN 의 vanishing gradient 문제를 해결하기 위해 Hochreiter and Schmidhuber(1997)가 LSTM 모델을 고안하였다. LSTM의 RNN과 다른 가장 큰 특징은 cell state(C)의 추가이다(Fig. 2). 현재 cell state(Ct)는 이전 cell의 정보(Ct-1)와 현재 입력 (Xt)을 토대로 계산된다. Ct-1에서 Ct로 전달되는 과정은 비선형 계산을 포함하지 않으며 이로 인해 sequence 길이가 길어 지더라도 역전파시 기울기값이 급격하게 하락하는 문제를 방지할 수 있다. ft는 forget gate로 Ct-1의 정보를 얼마나 보전할 것인가를 결정한다. it (input gate)와 ot(output gate)는 각각 Xt를 Ct 와 ht에 추가하는 역할을 한다. 각 gate와 state에대한 구조와 식은 아래와 같다.
여기서, W와 b는 각각 가중치(weight)와 편향(bias)이다.
2.3 Experiment Condition
본 연구에서는 모델 매개변수(Case 1)와 예측변수(Case 2) 를 이용하여 case study를 진행하였다. 각 case 조건은 Table 2와 같다. 예측 시간 간격은 1, 6, 12, 24시간/1, 3, 5, 10일로 장·단기 DO 농도를 예측하였다. 첫 번째 case study는 모델 매개변수를 다양하게 설정하여 예측 정확도를 비교하였다. 이를 통해 DO 농도 예측의 최적 모델 조건을 찾고자 하였다. 두 번째 case study는 모델 매개변수를 hidden node = 10, Epoch = 300, Sequence length = 1로 고정하고 예측변수를 3가지(모든 변수/DO/DO + α)로 나누었다. 여기서 DO + α 는 DO 농도와 1가지 변수를 같이 사용했을 때를 의미한다. 이를 통해 DO 농도 예측에 적합한 환경인자가 무엇인지 검토하였다.
3. 결과
3.1 모델 조건 - DO 농도 예측 분석(Parameter)
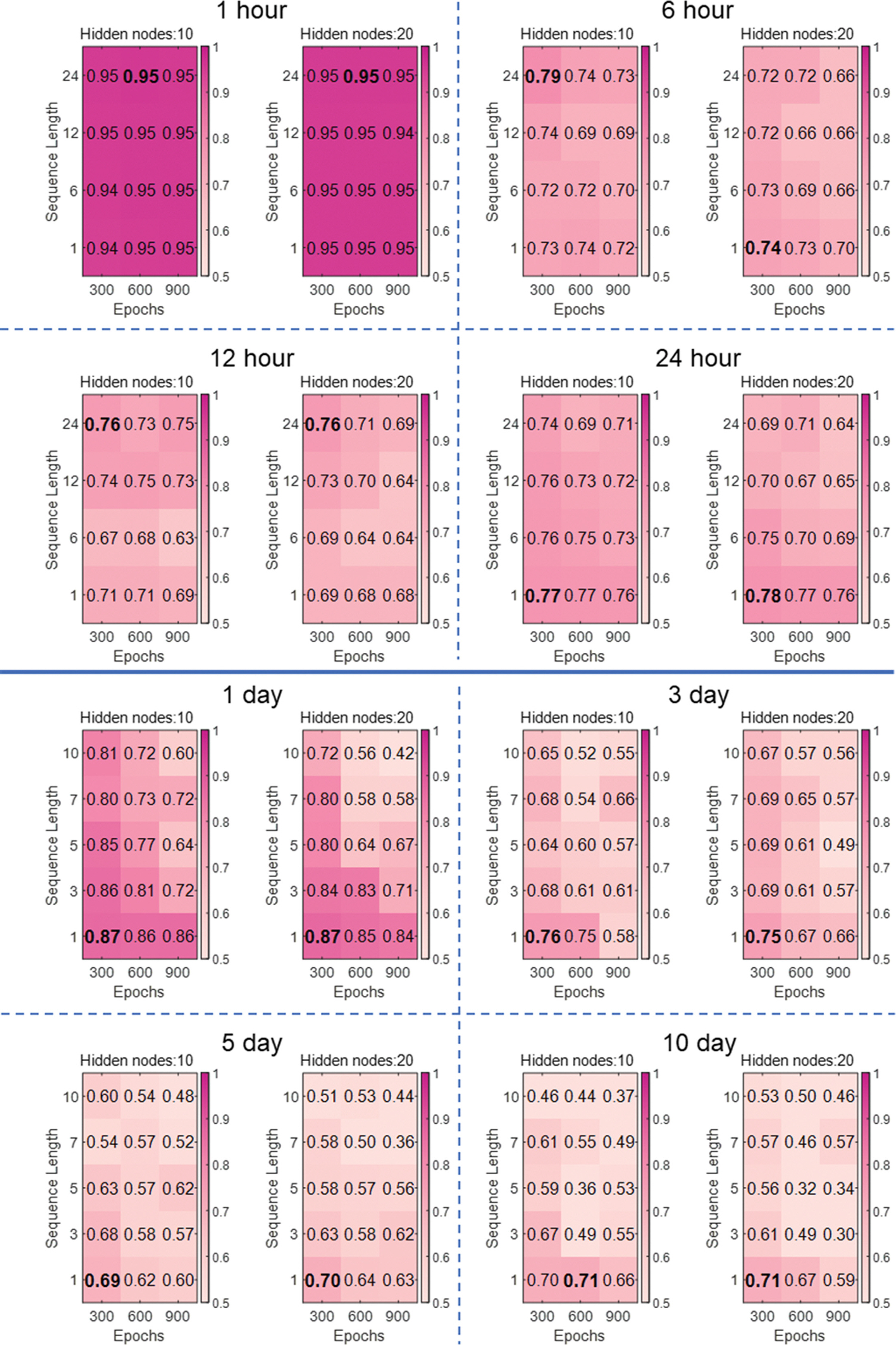
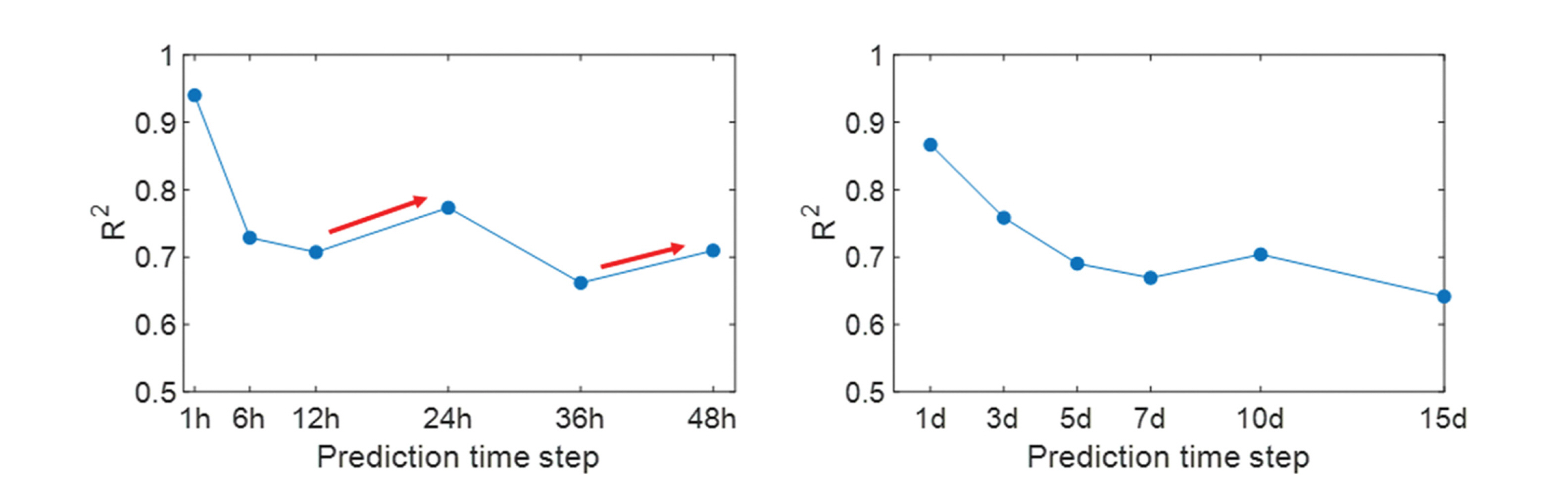
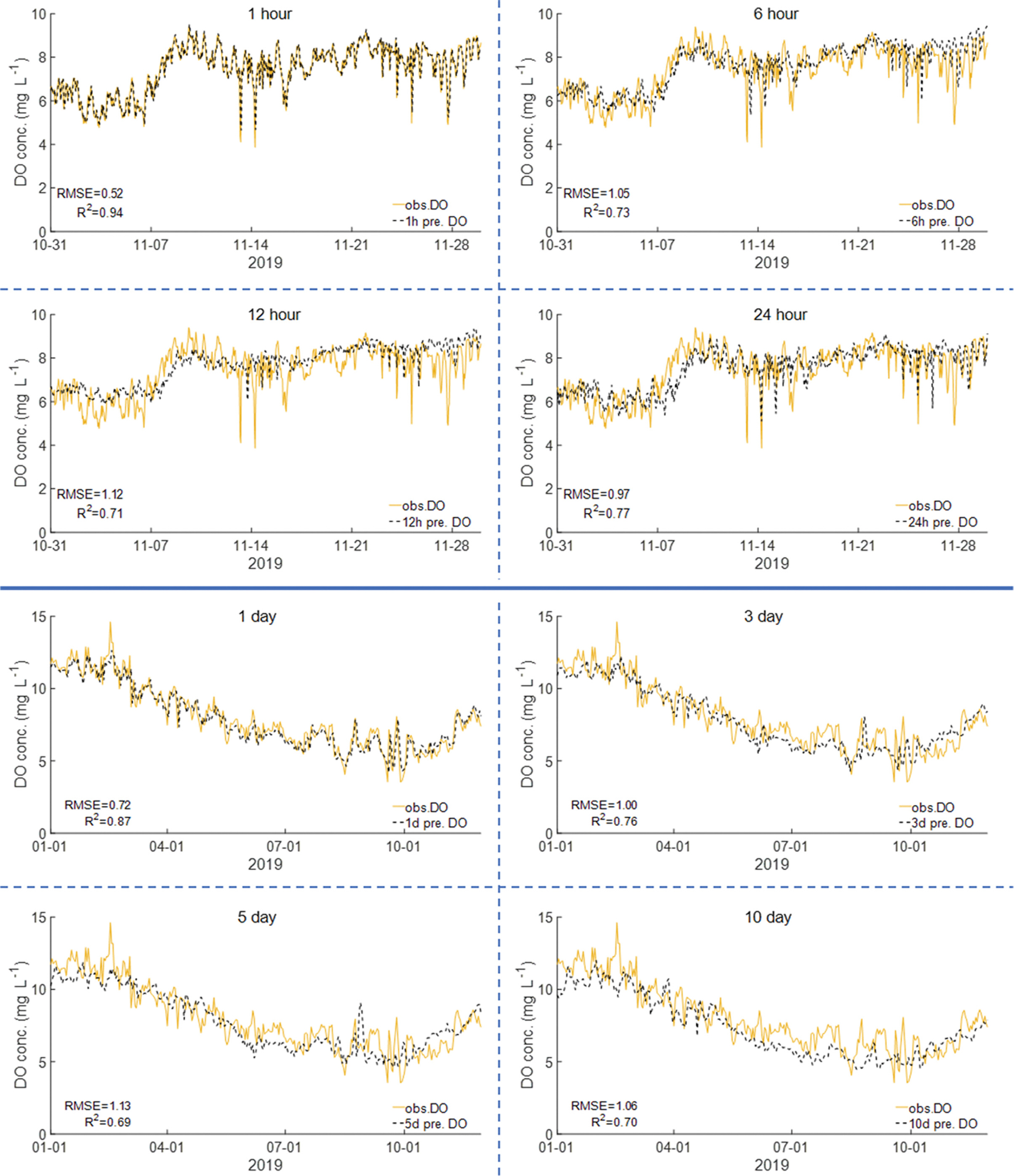
Case study 1의 모델 매개변수별 예측 정확도는 결정계수 (R2)로 Fig. 3에 나타내었다. 시간 예측과 일 예측 모두에서 Hidden node에 따른 R2 값 차이는 매우 작았으며, 300 Epoch 에서 가장 높은 정확도를 보였다. 시간 예측에서 Epoch = [300, 600, 900]의 평균 R2는 각각 [0.79, 0.77, 0.76]이었으며, 일 예측에서는 각각 [0.68, 0.60, 0.57]로 나타났다. 가장 적은 300 Epoch에서 높은 정확도를 보인 것은 600, 900 Epoch에서 과적합(Overfitting)이 발생한 것으로 판단된다. 과적합이란 기계학습이 과도하게 수행되어 모델이 학습 데이터에 과하게 맞춰진 현상을 말한다. 과적합이 발생하면 학습 데이터에 대한 오차는 감소하지만, 검증 데이터에 대한 오차는 증가 한다. Sequence length별 일 예측 정확도는 Sequence length = [1, 3, 5, 10]의 평균 R2 = [0.72, 0.64, 0.59, 0.60]으로 나타나 1 Sequence length가 가장 높은 정확도를 보였다. 시간 예측에서는 Sequence length = [1, 6, 12, 24]의 평균 R2는 각각 [0.78, 0.76, 0.77, 0.78]로 1, 24 Sequence length가 높은 정확도를 보였다. 시간 예측에서 예측 시간 간격별 정확도는 [1시간, 6시간, 12시간, 24시간] 예측의 평균 R2는 각각 [0.95, 0.71, 0.70, 0.73]으로 나타났다. 예측 시간 간격이 길어질수록 정확도가 떨어지는 모습을 보였다. 단, 24시간 예측의 경우 앞선 6시간, 12시간 예측보다 높은 R2 값을 보였는데, 이는 DO 농도의 일주기 변화에 따른 것으로 판단된다. 이에 대한 해석을 위해 예측 시간 간격을 48시간까지 확장 하여 R2 값을 계산하였다(Fig. 4). 또한, 예측 시간 간격을 15일까지 확장하여 일 예측 R2 값을 계산하였다. 일 예측 결과 에서 [1일, 5일, 15일] R2는 각각 [0.87, 0.76, 0.64]로 예측 시간 간격이 늘어날수록 정확도가 떨어지는 결과를 보였다. 반면에 시간 예측에서는 24시간 주기로 예측 정확도가 올라가는 결과를 보였다. 12시간과 24시간 R2 값은 각각 0.71, 0.77로 R2 값이 증가했으며, 36시간과 48시간 R2 값도 각각 0.66, 0.71로 R2 값이 증가하는 결과를 보였다. 이러한 결과는 Lim et al.(2020)의 연구에서도 확인할 수 있다.
예측 정확도가 가장 높은 모델 조건인 Epoch = 300, Sequence length = 1, Hidden node = 10의 DO 농도 예측값과 관측값의 시계열 비교 그래프를 Fig. 5에 나타내었다. 시간 예측과 일예측 각각 약 1달, 1년 동안의 예측 결과를 나타내었다. 시간 예측에서 예측 시간 간격이 짧은 1시간 예측값의 경우 관측값과 잘 일치하는 모습을 보였다. 예측 시간 간격이 6, 12 시간으로 길어질수록 모델의 정확도는 떨어지고 예측값이 관측값으로부터 이격되는 모습을 보였으나, 24시간 예측에서 다시 정확도가 올라가는 결과를 보였다. 이는 앞서 설명한 DO 농도의 일주기 변화에 따른 결과로 판단된다. 일 예측에서는 1일 예측의 경우 1년 동안의 DO 농도 변화를 잘 예측하는 모습을 보였으나, 예측 시간 간격이 3, 5일로 늘어날수록 그정확도는 점점 떨어지는 결과를 보였다. 단, 10일 예측 결과는 5일 예측 결과와 유사한 정확도를 보였는데, 이에 대한 해석을 위한 후속연구가 필요할 것으로 사료된다.
3.2 예측변수 - DO 농도 예측 분석(Predictor)
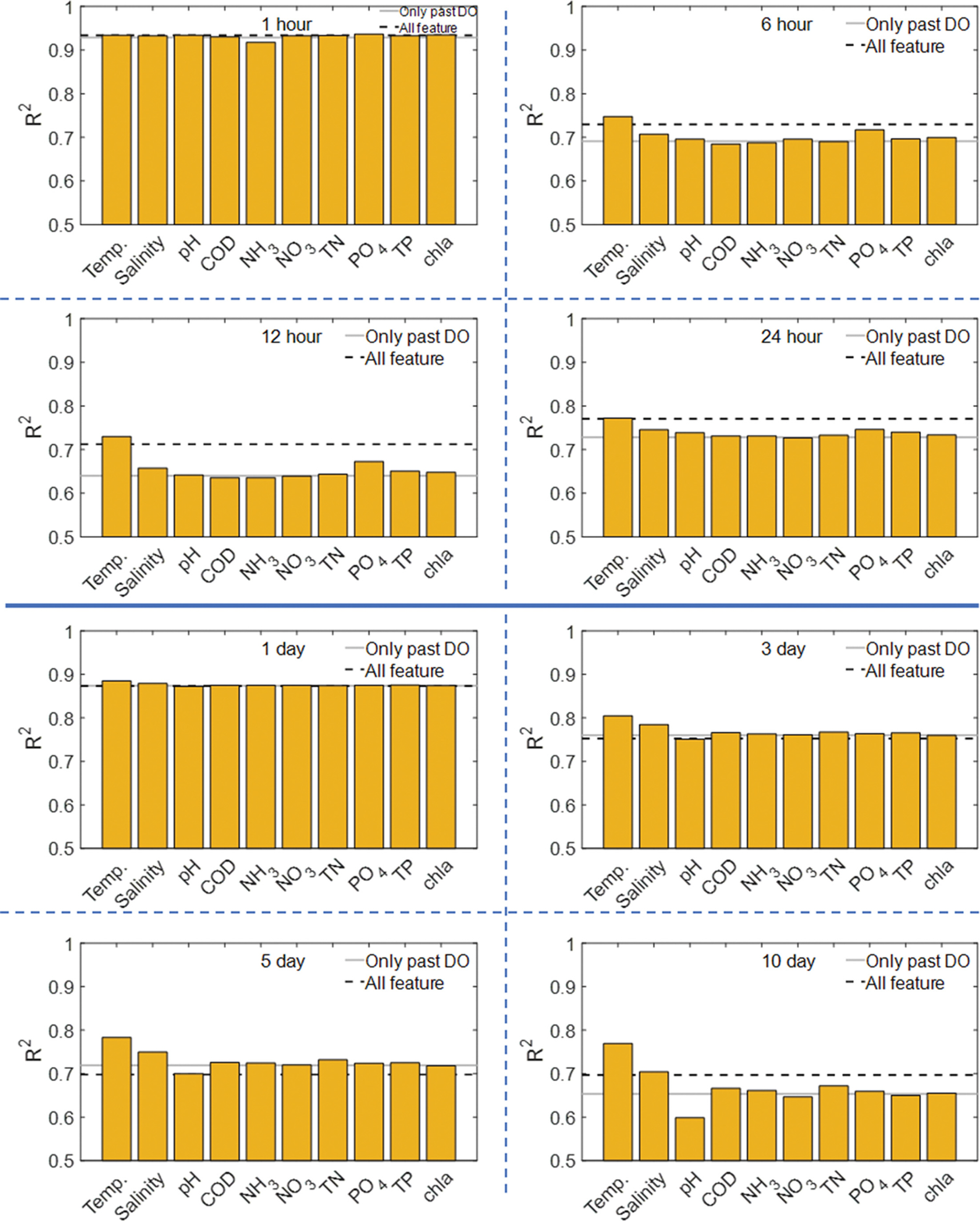
Case study 2의 예측변수별 예측 정확도는 R2로 Fig. 6에나타내었다. 예측변수로 모든 feature(All feature)를 사용했을 때와 DO 농도(Only past DO)만을 사용했을 때 R2 값을 각각 점선과 실선으로 제시하였으며, DO 농도와 1가지 feature (DO + α)를 예측변수로 사용했을 때의 결과는 막대 그래프로 나타내었다. 1시간 예측에서 예측변수별 R2는 0.92~0.94의 범위로 미소한 차이를 보였다. 6시간, 12시간, 24시간 예측에서는 DO + 수온을 예측변수로 했을 때 가장 높은 정확도를 보였으며, All feature를 예측변수로 했을 때와 비슷한 R2값을 보였다. 6시간, 12시간, 24시간 예측의 DO + 수온 R2 값은 각각 0.75, 0.73, 0.77이었으며, DO + 수온 외 feature들의 R2 값 범위는 각각 0.68~0.72, 0.64~0.67, 0.73~0.75, All feature의 R2는 각각 0.73, 0.71, 0.77로 나타났다. 이러한 결과는 일 예측에서도 유사하게 나타났다. 일 예측의 DO + 수온 결과는 All feature를 예측변수로 사용한 결과보다 확연히 높은 정확도를 보였다. 1일, 3일, 5일, 10일 예측에서 DO + 수온의 R2 값은 각각 0.88, 0.80, 0.78, 0.77이었으며, All feature의 R2는 각각 0.87, 0.75, 0.70, 0.70으로 나타났다.
DO 농도와 다른 feature간의 상관 계수(R)의 절대값을 Table 3에 나타내었다. |R| 값에 따른 두 변수간의 상관성은 일반적으로 다음과 같다(Zhou, 2004). R = 0.0~0.2: no correlation, 0.2~0.4: weak correlation, 0.4~0.6: moderate correlation, 0.6~0.8: Strong Related, 0.8~1.0: Extremely strong correlation. DO 농도와 feature들간의 |R| 값과 feature 별 DO 농도 예측 정확도는 유사한 결과를 보여주었다. DO 농도와 수온간의 |R| 값은 시간, 일 자료 결과 각각 0.78, 0.84로 가장 높은 상관성을 보였다. DO 농도의 시간 예측과일 예측에서 DO + 수온을 예측변수로 했을 때 가장 높은 정확도를 보여준 것은 DO 농도와 수온의 높은 상관성에 기인한 것으로 판단된다. 마찬가지로 시간 자료에서 DO 농도와 PO4 농도간의 |R| 값이 수온 다음으로 높은 0.71이었으며, DO + PO4의 [6시간, 12시간, 24시간] 예측 결과도 R2 = [0.72, 0.67, 0.75]로 DO + 수온 다음으로 높은 정확도를 보였다.
4. 결론
본 연구에서는 LSTM 모델을 활용하여 낙동강 하구역의 DO 농도 예측을 위한 최적 모델 조건과 적합한 예측변수를 찾기 위한 Case study를 수행하였다. 모델 매개변수 case study를 통해 DO 농도 예측의 최적 모델 조건을 찾고자 하였다. 예측변수 case study를 통해 DO 농도 예측에 적합한 환경인자가 무엇인지 검토하였다. 모델 매개변수 case study 결과, Hidden node에 따른 예측 정확도 차이는 매우 작았다. Epoch은 300, 600, 900을 고려하였으며 시간 예측과 일 예측 모두에서 Epoch = 300에서 높은 정확도를 보였다. Sequence length별 정확도는 시간 예측과 일 예측 각각 24, 1 Sequence length에서 높은 정확도를 보였다. 예측변수 case study 결과, 시간 예측과 일 예측 모두에서 DO + 수온을 예측변수로 했을때 가장 높은 정확도를 보였다. 상기 결과로부터 DO 농도 예측에 적합한 LSTM 모델 조건과 예측변수를 확인하였다. 단, 상기 결과가 낙동강 하구역에 한정된 결과일 가능성을 고려했을 때 다른 지점 자료를 토대로 비교분석이 필요할 것으로 판단된다.