






1. 서 론
온실가스 배출 증가에 의한 영향으로 가까운 미래의 기후변화가 예상되는 상황에서 기후변화의 지표로 기온이 가장 활발하게 사용되고 있다. 더불어 기후변화로 인한 해양 환경변화도 예상되는 상황에서 해양 환경변화의 지표로 해수면 변화가 가장 활발하게 사용되고 있으나, 해양 생태환경의 관점에서는 수온이 해양 생태환경을 결정하는 중요한 지표이기 때문에 보다 적절한 지표로 판단된다(IPCC, 2007; Cho & Lee, 2012). 특히 연안의 수온변화는 기온변화와 직접적인 관계가 있기 때문에 수온변화에 의한 연안의 환경변화는 기온변화와 관련지을 수도 있다. 연안의 기온 및 수온변화는 연안에서의 열에너지 수지분석을 통하여 예측이 가능하지만 열에너지 분석에 사용되는 입력 자료의 불확실성에 따른 오차전달도 예상되기 때문에 연안의 대기와 해양환경을 대표하는 기온과 수온을 변화의 지표로 이용하는 것도 적절할 것으로 판단된다. 기상자료에 대한 통계적인 분석, 특히 관측 자료에 근거한 발생빈도 분포분석은 기온변화 양상과 수온변화 양상을 파악할 수 있기 때문에 매우 중요한 내용으로 판단되고 있다. McCloy and Dolan(1973)은 미국 대서양 북부 연안의 수온과 기온자료의 관계를 연구하였으나 전반적으로 이 분야의 연구는 미진한 실정이다(Storch & Zwiers, 1999).
계절 변화가 뚜렷한 연안의 기온변화를 정규분포함수로는 표현하는 것은 한계가 있으며(Nese, 1994), 수온과 같이 Bimodal분포함수 형태를 가지는 것으로 추정할 수 있으나, 그 추정 모수에서는 차이를 보일 것으로 예상할 수 있다. Cho et al.(2004)과 Jeong et al.(2008)은 조위 분포함수 추정에 Bi-modal 분포함수를 이용하였으며, Jeong et al.(2013)은 수온 분포함수 추정 등에 Bi-modal 형태의 분포함수를 이용하였으며, Grace & Curran(1993)은 일 최대 기온자료의 월별 분포함수로 bi-normal 분포함수를 제시한 바 있다. 다수의 첨두를 가진 이러한 분포함수는 Gaussian 혼합모형(Gaussian mixture model, GMM)의 특정한 형태로 다양한 자료의 분포함수 추정에 이용되고 있다(Huang & Chau, 2008; Grace & Curran, 1993). 이 모형은 혼합하는 함수의 개수 또는 표현하고자 하는 첨두의 개수에 따라 차수를 표현할 수 있기 때문에 Bi-modal 분포함수는 GMM(2) 함수로 간략하게 표현할 수 있다.
본 연구에서는 우리나라 연안에 위치한 주요 8개 지점(인천, 군산, 목포, 여수, 부산, 제주, 포항, 강릉) 기상대의 기온 자료를 이용하여 발생 빈도 분포함수를 추정하였다. 기후분석에 이용되는 적절한 기간에 해당하는 30년 정도의 장기 기온 자료를 이용하여 빈도분포함수를 Bi-modal 분포함수를 가정하여 최적 모수를 추정하고, 그 매개변수와 기온자료의 관계분석을 수행하였다. 또한 Jeong et al.(2013) 등에 의하여 수행된 수온 분포함수와의 비교·분석을 수행하였다. Bi-modal분포함수는 꼬리부분에서 다소 큰 오차를 보이는 한계가 있으나 정규분포보다 적합한 매개변수를 제시하여 매개변수 분석을 통한 전반적인 발생빈도 변화 양상을 추정할 수 있을 것으로 판단된다.
2. 기온 관측자료
우리나라 연안의 기온자료는 가장 기본적이고 측정이 간단하기 때문에 다양한 기관에서 보유하고 있으나, 품질검정과정을 거쳐 제공되는 장기간의 자료는 기상청 자료이다. 기온자료의 발생빈도 분포를 추정하기 위해서는 단기간의 자료보다는 장기간의 자료가 필요하기 때문에, 본 연구에서는 장기간의 기온자료가 제공되는 기상청 일평균(daily-mean) 기온자료를 이용하였다(KMA, 2014). 연구에 사용된 자료는 우리나라 연안 총 8개 지점의 자료로, 각각의 지점은 인천, 군산, 목포(이하 서해안 3개 지점), 여수, 부산, 제주(이하 남해안 3개 지점), 포항, 강릉(이하 동해안 2개 지점)이다. 관측지점의 위치 및 관측기간 등의 기본적인 정보는 Table 1에 제시하였으며, 관측기간에서 결측자료가 아주 적은 비중을 차지하는 1981년부터 2013년까지 33년 동안의 자료를 선택하여 연구에 이용하였다.
Table 1.
Basic information of the meteorological stations of the air temperature data
3. 분석방법
일단위(daily) 기온자료는 자료의 자기상관영향이 크게 나타나고 있는 시계열 자료(time-series data)에 해당한다. 따라서 어떤 확률분포함수를 추정하는 기본조건에 해당하는 자료의 독립성이 결여되어 있다. 그러나 자연에서 관측되는 대부분의 자료는 어느 정도의 자기상관(auto-correlation)을 가지기 때문에 발생빈도 분포측면에서 분포함수를 추정하게 된다. 분포 함수를 추정하기에 앞서 개략적인 자료 변화 양상 분석을 위하여 자료의 시계열도(time-series plot)를 Fig. 1에 제시 하였다. 기온자료가 아주 장기간의 자료이기 때문에 일 또는 주 단위의 작은 시간변동 범위를 보기에 적합하지 않으나 전체적인 변화양상 및 큰 규모의 결측 양상 등은 간단하게 판단할 수 있다. Fig. 1 에서 볼 수 있는 바와 같이 전체적으로 1950년도의 한국전쟁 기간을 제외하고는 특별한 결측 구간이 발생하지 않고 있음을 알 수 있다. 또한 계절변화가 뚜렷하기 때문에 매년 기온의 최대-최소가 반복되는 양상을 보이고 있음을 알 수 있다.
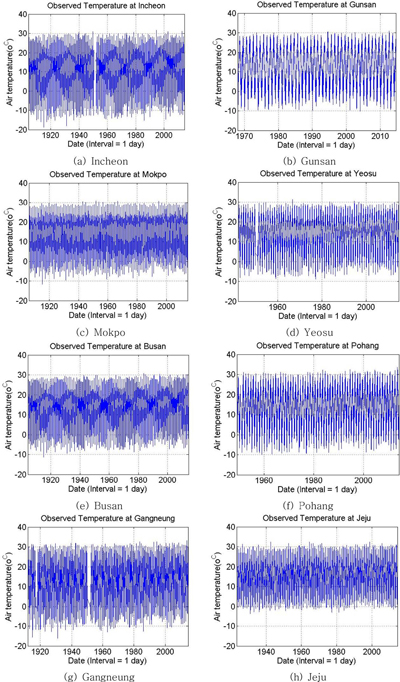
또한 년 최저기온은 인천과 강릉이 상대적으로 다른 지점에 비하여 낮고, 제주는 높게 나타나고 있으며, 년 최고기온은 지점별로 큰 차이를 보이지 않는다.
이러한 기온자료의 시계열 도시는 결측 구간(missing interval), 이상자료(outliers) 등의 정보는 쉽게 파악할 수 있으나, 시간에 따른 자료의 변화추이 및 기본적인 통계정보, 분포 양상 등은 파악할 수 없다.
3.1 도수분포
어떤 확률변수의 분포함수는 다양한 통계적인 추론을 위한 가장 기본적이고 중요한 정보로 자료로 부터 추정하는 것이 일반적이다. 이러한 확률밀도함수의 추정에 관한 연구는 통계적으로 모수적(parametric) 방법과 비모수적(non-parametric) 방법으로 구분할 수 있다(Raccine, 2008; Silverman, 1986).
본 연구에서는 대표적인 비모수적 방법에 해당하는 히스토그램을 이용하여 기온자료의 개략적인 분포형태를 분석하고, 빈도분포함수의 빈도자료를 분석에 사용된 자료의 개수로 나누어 확률분포 함수(밀도분포 함수, density histogram)로 계산하였다. 밀도 도수분포는 곡선 아래 면적으로 도수분포를 나눈 도수분포는 면적이 1(one)이 된다.
히스토그램을 이용하여 분포를 추정하는 경우, 분포 형태는 2개의 모수 즉, 계급의 원점(시작점, to)과 계급 폭(bin width, h)에 의하여 결정된다. 계급 폭은 ‘smoothing parameter’라고도 부르며, 도수분포의 유연도를 결정하게 된다. 즉, 계급 폭이 작으면, 계급의 높이의 변화가 심하고, 계급 폭이 크면, 계급의 높이의 변화가 작다. 동일 자료인 경우에도 계급 폭의 크기에 따라 상이한 형태의 도수분포도가 생성되고, 적절한 계급 폭을 사용하여야 자료의 분포형태를 쉽게 파악할 수 있다(Martinez et al., 2011). 본 연구에서는 자료 개수와 표본 표준편차를 사용한 관계식 (1)을 이용하여 계급 폭을 결정하였다.

여기서, n은 분석 자료의 개수, s는 표본 표준편차이다.
3.2 분포 함수
우리나라는 여름의 고온과 겨울의 저온이 반복되는 지역으로 도수분포 형태도 저온과 고온의 특정 기온 부근에 빈도수가 집중되는 쌍봉(double-peak) 형태로 표현될 수 있다. 따라서, 본 연구에서는 도수분포도가 쌍봉(double peak) 형태임을 고려하여, 기온자료의 빈도분포 함수(pT(x))로는 평균과 분산이 서로 다른 2개의 정규분포함수를 선형 결합한 형태, 즉 6개의 매개변수를 가진 Gaussian Mixture Distribution(GMD) 함수형태를 제안하였다. 이 식은 다음 식 (2)와 같이 표현된다.
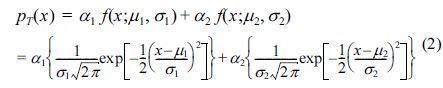
여기서, α1, α2는 scale parameter로 α1+ α2= 1의 관계가 있으며, μ1, μ2는 각각 평균으로 첨두의 위치를 결정하는 매개변수이며, σ1, σ2는 각각 표준편차로 각각의 첨두 부근의 자료에 대한 분산정보와 관련이 있는 매개변수로 간주할 수 있다. 이 값이 작을수록 자료의 분포는 집중되기 때문에 꼬리 부분은 급격하게 감소하는 양상을 보이게 된다.
3.3 분포함수의 매개변수 추정
전술한 확률변수의 주 특성값들, 즉, 평균 및 표준편차 등은 가장 일반적인 자료로 관측 정점별로 잘 알려져 있거나, 쉽게 산정할 수 있다. 본 연구에서는 MATLAB 프로그램을 이용하여 8개 연안 정점의 관측자료로부터 평균 및 표준편차 등 주 특성값을 산정하였다. 이들 주 특성값과 기온 분포 매개변수의 관계는 다음과 같은 최소자승법을 이용하여 도출하였다. 즉 기온자료가 가용한 정점(본 연구의 경우, 8개 정점)의 주 특성값(본 연구에서는 평균, 표준편차, 왜곡계수 사용) 행렬을 Hi,j(i =정점 인자, j =주 특성값 인자; known), 기온 분포함수의 매개변수 행렬을 Pi,k(i = 정점 인자, k = 매개변수 인자; known)라고 정의하고, 분포함수의 매개변수가 주 특성 값의 선형조합으로 표현된다고 가정하는 경우 다음과 같은 관계 식 (3)이 성립된다.

여기서, Cj,k는 선형조합 계수로 구성된 미지의 행렬(unknown)이다. 위 식을 정리하면, 식 (3)을 이용하여 식 (4)와 같이 최적 선형조합 계수 행렬(Cj,k)을 계산할 수 있다.
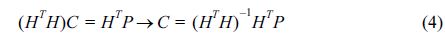
여기서, HT는 행렬 H의 전치행렬이고, (HTH)−1는 (HTH)의 역행렬이다.
4. 결과 및 토의
연안 8개 지점의 기온 자료를 분석하는 과정은 Fig. 2와 같다.
4.1 자료의 기본적인 통계정보
자료의 분포양상과 관련되어 있는 기본적인 통계정보는 평균, 표준편차, 왜곡도 계수(skewness coefficient)로 제한하여 산정하였으며, Table 2에 제시하였다. 전체적으로 평균은 12~15oC 내외이며, 표준편차는 7.7~9.9oC 범위를 보이고 있으며, 모든 점에서 왜곡도 계수가 음(-)의 값으로 나타나 분포가 우측으로 왜곡된 형태를 보이고 있음을 알 수 있다.
4.2 도수분포도
도수분포도를 작성하기 위해서는 먼저, 서로 인접한 자료값을 집단화하여 전체 자료 집합을 몇 개의 그룹으로 나눈다. 이를 위하여 전체 자료의 범위를 몇 개의 계급(class, bin)으로 나누는 것이 필요하다. 본 연구에서는 식 (1)을 이용하여 최적 계급 폭(bin width, h)을 산정하였으며, 한국 연안 주요 8개 정점의 기온 도수분포도는 Fig. 3과 같다.
Fig. 3에서 볼 수 있는 바와 같이, 빈도분포는 전반적으로 Bi-modal 분포형태를 보이고 전반적으로 2개의 첨두가 보이고 있음을 알 수 있다. 목포 및 제주지점에서는 뚜렷하지는 않으나 3개 정도의 첨두가 보이는 것으로 추정할 수 있다. 한편 저온 영역의 완만한 분포형태에 비하여 고온 영역은 상대적으로 급격하게 빈도가 감소하고 있음을 알 수 있다. 이러한 경향은 Jeong et al.,(2013)이 분석한 수온의 빈도분포 양상, 즉 고온 영역의 완만한 감소와 저온 영역의 0oC 지점에서의 급격한 감소와는 상이한 양상을 보이고 있음을 알 수 있다.
Table 2.
Statistical information of the air temperature data in Korean coastal areas
4.3 분포 함수의 매개변수 추정
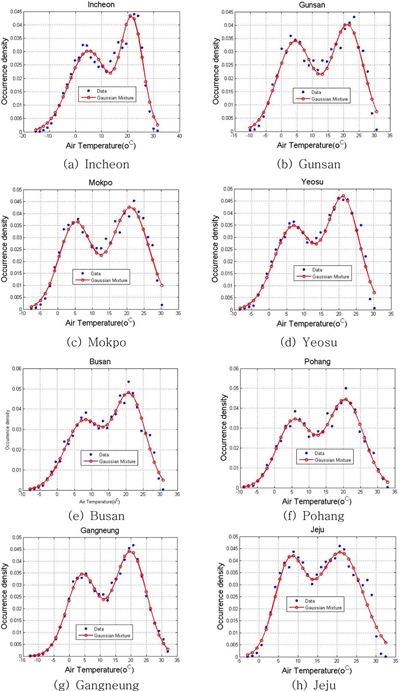
연안 8개 정점의 기온 상대도수분포도를 분석한 결과, Fig. 3에 도시된 바와 같이 대부분 쌍봉(double peak) 형태이다. 따라서 기존의 Single-modal 분포함수를 사용하기에는 한계가 있기 때문에 기온자료의 빈도분포 함수로는 평균과 분산이 서로 다른 2개의 정규분포함수의 합의 형태, 즉 6개의 매개변수를 가진 Gaussian Mixture Distribution(GMD) 함수형태를 제안하였다(식 (2) 참조).
제안된 후보 분포함수의 최적 매개변수는 MATLAB Optimization 도구상자에서 제공하고 있는 함수인 ‘lsqnonlin’를 이용하여 추정하였다. 비선형 최적화 문제는 모수의 초기값 지정이 중요하기 때문에 본 연구에서는 위치모수는 Histogram형태에서 보여지는 첨두 영역을 기준으로 다른 영역을 침범하지 않는 범위로 지정하였으며, 분산모수에 해당하는 모수는 간단하게 양수로 지정하였다. 연안 8개 정점의 기온 자료에 대하여 식 (2)의 매개변수를 추정한 결과는 Table 3에 제시하였다. 히스토그램 분포에서 이미 예상한 바와 같이, 목포 및 제주지점의 표준편차 매개변수를 다른 지점의 매개변수 수치와 비교한 결과 σ1은 확연하게 작고, σ2는 크게 나타나고 있다. 한편, 관측 자료를 이용한 분포함수(밀도 도수분포도, density histogram), 추정된 매개변수를 사용하여 산정한 GMD 함수형태의 곡선을 Fig. 4에 동시에 도시하였다.
Fig. 4에서 볼 수 있는 바와 같이 정규분포 함수 가정은 자료의 중앙 부분과 꼬리 부분에서 매우 큰 차이를 보이고 있음을 알 수 있으며, 본 연구에서 제안한 Bi-modal(Gaussian Mixture(2) Model) 형태의 분포함수는 뚜렷하게 보이는 대략 2개의 첨두 형태 재현은 우수한 것으로 판단되나, 2개 이상의 첨두가 존재하는 제주 및 목포지점의 분포양상 재현에는 한계가 있는 것으로 판단된다. 또한 꼬리 영역의 급격한 감소 형태 재현에도 한계가 있는 것으로 판단된다. 이러한 문제는 3개 다수의 첨두를 표현할 수 있는 Multi-modal 분포함수를 이용하거나 정규분포만의 Mixture 형태가 아닌 가용한 다른 다양한 분포함수(Log-Normal 분포함수, Rayleigh 분포함수, Weibull 분포함수 등)의 조합을 통하여 최적 분포함수 형태를 도출할 필요가 있을 것으로 판단된다.
Table 3.
Optimal parameters of the GMD(2) distribution functions for the daily air temperature data
4.4 주 특성 값과 GMD 분포 매개변수의 선형조합 계수 추정
식 (4)를 이용하면 평균 및 분산과 GMD 분포함수의 매개변수의 관계를 표현하는 최적 계수를 추정할 수 있다. 여기서, 주 특성 행렬 Hi,j은 (8×3) 행렬(여기서, 8 =정점의 개수, 3 =주 특성 값, 평균, 표준 편차 그리고 왜곡도)이며, 매개변수 행렬 Pi,k도 (8×6) 행렬(여기서, 6 = 매개변수의 개수)이 되기 때문에 최적 선형조합 계수행렬 Cj,k은 (3×6) 행렬로 다음 식(5)과 같다.

따라서 GMD 분포함수의 매개변수는 각각 다음과 같은 식 (6)으로 계산할 수 있다. 식 (6)으로 계산되는 매개변수 수치는 자료의 분포함수에서 수학적으로 추정한 최적 매개변수와 자료의 기본적인 통계정보의 선형관계로부터 추정되기 때문에 최적 매개변수를 이용한 경우보다 분포 재현수준이 감소하게 된다. 그러나 분포 매개변수의 물리적인 의미부여가 가능하게 된다.

한편 식 (6)에서 제시되는 가중계수(α1, α2)는 다른 매개변수를 이용하여 추정할 수 있는 식이 제시(Ko et al., 2013)되어 있으므로, 그 식을 이용하여 추정할 수도 있다. Ko et al.(2013)이 제시한 식을 이용하여 가중계수를 계산하는 경우, 가중계수 추정정도가 크게 향상되는 것으로 파악되었다.
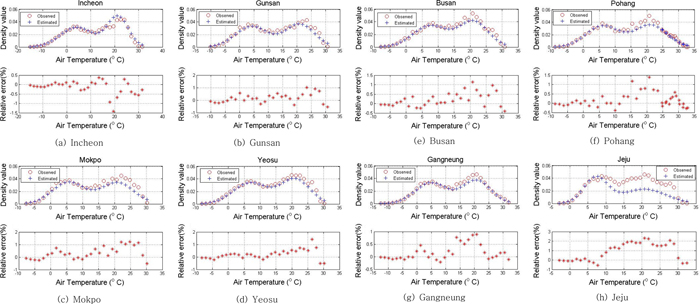
추정된 확률밀도 함수는 기상대의 기온자료의 통계적 정보를 이용하여 추정한 확률밀도 함수와 비교하여 오차를 분석하였다(Fig. 5 참조). 관측 자료를 이용한 확률밀도 함수와 본 연구에서 개발한 공식(식 (6))을 이용한 확률밀도 함수를 비교한 결과 전반적으로 매우 우수하게 일치하는 양상을 보이고 있으나, 고온 영역의 꼬리 부분에서는 오차가 크게 증가하고 그 변동범위도 크게 나타나고 있음을 알 수 있다. 특히 목포 및 제주지점의 고온영역 분포양상은 그 재현에 한계가 뚜렷하게 나타나고 있다.
5. 결론 및 제언
본 연구에서 우리나라 연안의 기온자료 빈도분포 함수로 제안한 Gaussian 혼합분포(Gaussian Mixture Distribution, GMD) 함수는 정규분포에 비하여 기온자료의 확률밀도함수로 매우 적합한 것으로 파악되었다. 또한 자료의 주 특성값인 평균, 표준편차, 왜곡도로부터 GMD(2) 분포함수의 매개변수를 산정하여 기온 자료의 빈도분포를 추정하는 공식을 개발하였다. 개발된 추정공식은 RMS 오차가 5% 정도로 관측자료를 이용한 결과와 우수한 일치를 보이고 있다. 본 공식은 장기간의 기온 자료가 없는 경우, 특정 정점의 기온 자료의 평균, 표준편차 그리고 왜곡도만을 이용하여 기온 분포함수를 간단하고 정확하게 추정하는 데 활용할 수 있다. 또한 장기간의 기온 분포함수 변화 양상을 파악하여 평균 기온만을 이용한 기후변화 양상분석이 아니라 빈도분포를 이용한 기후변화 양상분석을 통하여 보다 다양하고 새로운 결과도출도 가능할 것으로 판단된다.
한편, 본 연구에서 제안한 Gaussian 혼합분포 함수 형태가 기온자료의 빈도분포 함수에서 첨두 형태 재현에는 우수한 결과를 보이고 있으나, 분포의 꼬리에 해당하는 부분에서는 재현성이 떨어지고 있다. 이 부분은 꼬리부분의 표현이 우수한 다양한 함수형태에 대하여 다각적으로 검토하는 연구가 필요가 있을 것으로 사료된다. 특히 제주의 경우, 다른 관측지점에 비하여 고온 자료가 많기 때문에 기온자료의 통계적 정보를 이용하여 확률밀도 함수를 추정하는 경우 특별한 주의가 필요하다.


